※ 本記事はDaily Dose of Data Scienceという、海外のデータサイエンス関連のブログ記事を参考にしています。(参考にした記事のリンク)
※ また、Qiitaにも同内容のものを投稿しています(Qiitaではコードの解説は載せていません)。
はじめに
分類タスクは機械学習において、一般的なタスクですが、最近その背景をきちんと勉強しないとと思う機会が増えてきました。
この記事では、分類モデルを二種類(確率的モデルとラベリングモデル)に分けて、それぞれの決定境界を可視化していくことで、特徴を見ていきたいと思います。
確率的モデルとラベリングモデル
機械学習の分類モデルは大きく分けて、特徴量から確率を計算することでラベルを推定するモデル(この記事では確率的モデルと呼びます)と、特徴量から何らかのルールに基づいてダイレクトにラベルを推定するモデル(この記事ではラベリングモデルと呼びます)が存在します。
以下の図にそれぞれの特徴をまとめました。
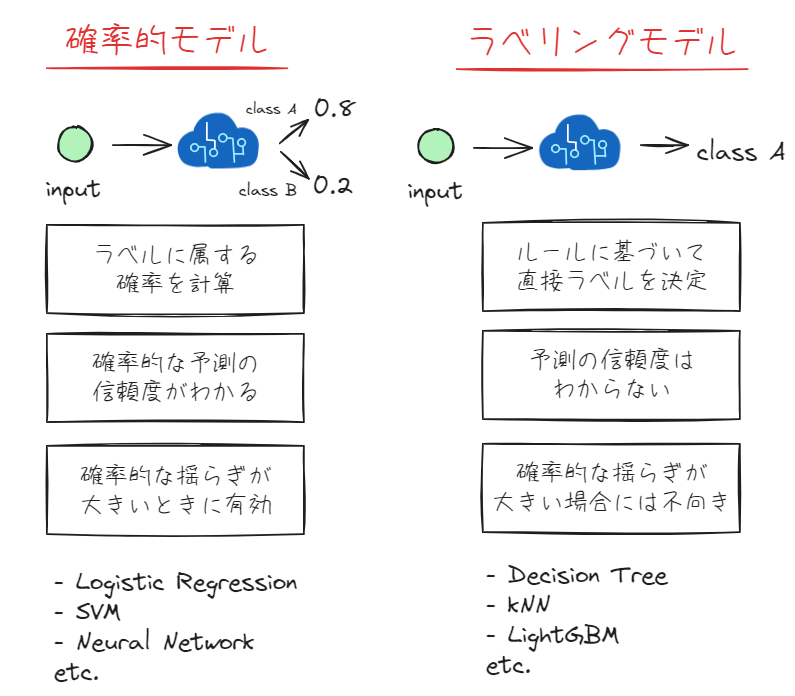
ここで大きな特徴としてはラベリングモデルでは確率の推定を最適化するように学習しているわけではないので、予測の信頼度(確率)を見る際には注意が必要であるということが挙げられます。
以下では、決定木を例にこの点を説明したいと思います。
決定木の確率計算(predict_proba)は何をしている?
上の「ラベリングモデルでは予測の信頼度はわからない」という説明を見て、

と思われた方もいるのではないでしょうか。
実際に、predict_probaによって決定木のモデルであっても確率を返してくれます。しかし、そのアルゴリズムは以下のようになっています。
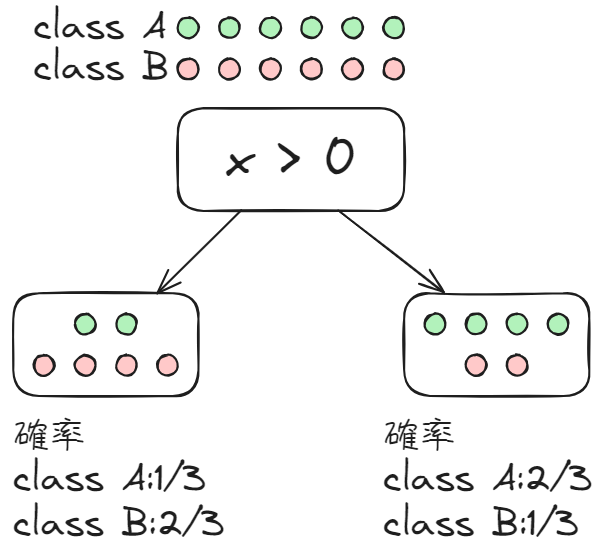
決定木では、学習したルールに基づいて訓練データを振り分けたときに、最後のノードで訓練データのそれぞれのラベルが存在する割合を計算しているにすぎません。
確率的モデルとラベリングモデルの決定境界の違い
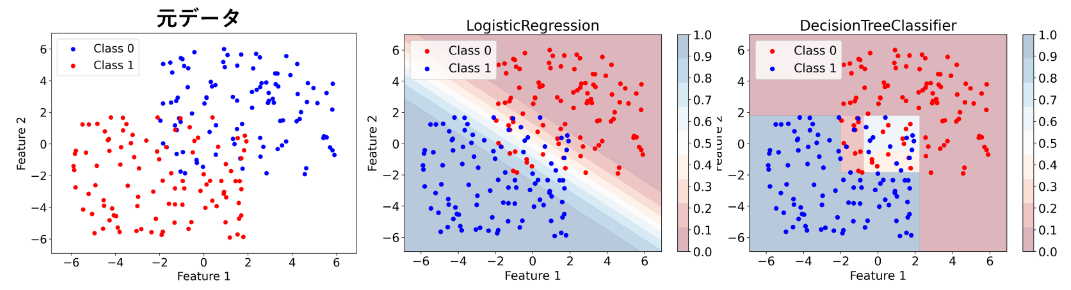
以上のことを踏まえて、確率的モデル(ロジスティック回帰)とラベリングモデル(決定木)によって、擬似データを使った分類問題がどのように解かれているかを図示した結果を示しました。(図中の色はpredict_probaによって計算された各点での確率値です)

※使用したコードは最後に載せています。
ロジスティック回帰では、連続的に確率を計算できるので、決定境界からの距離などモデルの予測に対する確信度がわかりやすいです。
しかし、決定木では確率値が離散的になっており、特に予測確率が0の領域と1の領域が隣接しています。また、離散的であるため、決定境界からの距離もわからず、境界付近に位置する点はノイズによってちょっと値が変わっただけで容易に確率0から1に変化する可能性もあります。
おわりに
今回は、分類モデルを確率的モデルとラベリングモデルの二種類に分けて、決定境界を可視化することでそれぞれの大きな特徴を見てみました。
二次元データに対して決定境界を可視化することで、勉強になることがとても多く、モデルの特徴の概観をつかむことができると思うのでぜひ試してみてください。
おまけ(SVC・Random Forestの決定境界)
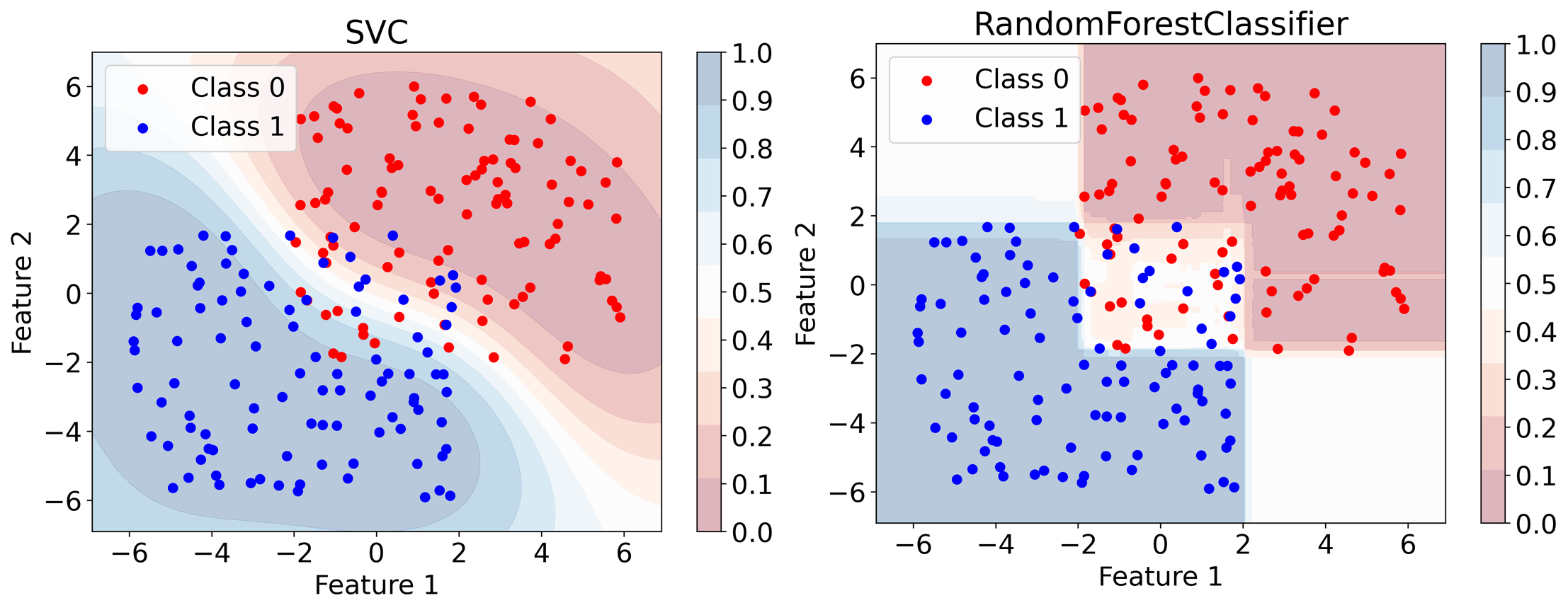
おまけとして、SVM(確率的モデル), Random Forest(ラベリングモデル)の決定境界も可視化してみました。
Logistic Regressionの場合は、決定境界から離れれば離れるほど(データがない領域でも)確率が1(or 0)に近づきましたが、SVMではデータがない領域に対してはモデルの予測確率が0.5に近づいていることがわかります。
また、Random Forestでは、第二象限、第四象限のデータがない部分に対する予測確率が0.5に近くなっており、Decision Treeよりは信頼性が高くなっている感じがありますが、離散的に決定境界付近で大きく予測確率が変化してしまうことについては、モデルの特性上どうしようもないことがわかります。
使用したコード
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
class ModelVisualizer:
def __init__(self, model, n_samples=100):
self.model = model
self.n_samples = n_samples
np.random.seed(0)
def generate_data(self, x1_range, y1_range, x2_range, y2_range):
x1 = np.random.uniform(*x1_range, self.n_samples)
y1 = np.random.uniform(*y1_range, self.n_samples)
self.data1 = np.column_stack((x1, y1))
x2 = np.random.uniform(*x2_range, self.n_samples)
y2 = np.random.uniform(*y2_range, self.n_samples)
self.data2 = np.column_stack((x2, y2))
self.X = np.vstack((self.data1, self.data2))
self.y = np.array([0] * self.n_samples + [1] * self.n_samples)
self.x_min, self.x_max = np.min(self.X[:, 0]) - 1, np.max(self.X[:, 0]) + 1
self.y_min, self.y_max = np.min(self.X[:, 1]) - 1, np.max(self.X[:, 1]) + 1
self.save_scatter_plot()
def fit_model(self):
self.model.fit(self.X, self.y)
def save_scatter_plot(self):
plt.figure(figsize=(8, 6))
plt.rcParams['font.size'] = 18
plt.scatter(self.data1[:, 0], self.data1[:, 1], color='blue', label='Class 0')
plt.scatter(self.data2[:, 0], self.data2[:, 1], color='red', label='Class 1')
plt.xlim(self.x_min, self.x_max)
plt.ylim(self.y_min, self.y_max)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.tight_layout()
plt.savefig(f'scatter.png', dpi=300, bbox_inches='tight')
def plot_decision_boundary(self):
xx, yy = np.meshgrid(np.linspace(self.x_min, self.x_max, 1000),
np.linspace(self.y_min, self.y_max, 1000))
if hasattr(self.model, "predict_proba"):
Z = self.model.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]
print(np.unique(Z))
else:
Z = self.model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(8, 6))
plt.rcParams['font.size'] = 18
contour = plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.bwr, levels=np.linspace(0, 1, 100))
plt.colorbar(contour, ticks=np.arange(0, 1.1, 0.1))
plt.scatter(self.data1[:, 0], self.data1[:, 1], color='blue', label='Class 0')
plt.scatter(self.data2[:, 0], self.data2[:, 1], color='red', label='Class 1')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title(f'{self.model.__class__.__name__}')
plt.legend()
plt.tight_layout()
plt.savefig(f'{self.model.__class__.__name__}.png', dpi=300, bbox_inches='tight')
tree_model = DecisionTreeClassifier(random_state=0, min_samples_leaf=10)
tree_visualizer = ModelVisualizer(tree_model)
tree_visualizer.generate_data((-2, 6), (-2, 6), (-6, 2), (-6, 2))
tree_visualizer.fit_model()
tree_visualizer.plot_decision_boundary()
logistic_model = LogisticRegression(random_state=0)
logistic_visualizer = ModelVisualizer(logistic_model)
logistic_visualizer.generate_data((-2, 6), (-2, 6), (-6, 2), (-6, 2))
logistic_visualizer.fit_model()
logistic_visualizer.plot_decision_boundary()書籍紹介
最近はこの本(見て試してわかる機械学習アルゴリズムの仕組み)を読んで勉強しています。
LightGBMなど新しめのモデルはないですが、機械学習をする上で誰もが通るモデルは一通り網羅されています。
教師なし学習の手法についても書かれているので、初学者の方にはおすすめです。

コメント